This post's content
When building an application, usually we query our database to retrieve the things we already know: what orders a client made or, more generally, what steps in the app flow have already been taken. However, to correctly address the user journey, it is often more important to query the database and retrieve data that informs us about what is missing: an item not yet in the basket, a missing email confirmation, or a pending payment. Understanding and addressing these missing steps is crucial to optimize the user experience and to drive app adoption.
The blog post showcases how to express such “missing steps” queries in PostgreSQL® SQL using as example the retrieval of users NOT having any activity.

Moreover, we are going to analyze the database's expected plan and actual performance of the various options, providing suggestions to handle such queries at scale.
TL;DR; The following are the five methods:
- Using
NOT EXISTS - Using
NOT IN - Using
<> ALL - With
LEFT JOINand checkingNULLs - Using
EXCEPT
What Does the NOT EXISTS Operator do in PostgreSQL?
First of all, let's explore what the NOT EXISTS operator does in PostgreSQL. The NOT EXISTS operator verifies that a specific value (or set of values) is NOT returned by a subquery. Some typical example, where you can use the NOT EXISTS operator are:
- Looking for users NOT generating traffic in the last month.
- Searching for items NOT already in the cart.
- Evaluating missing steps in a procedure.
All the above, and many other, examples can be defined using the NOT EXISTS operator. The following is a visual representation of the users example.
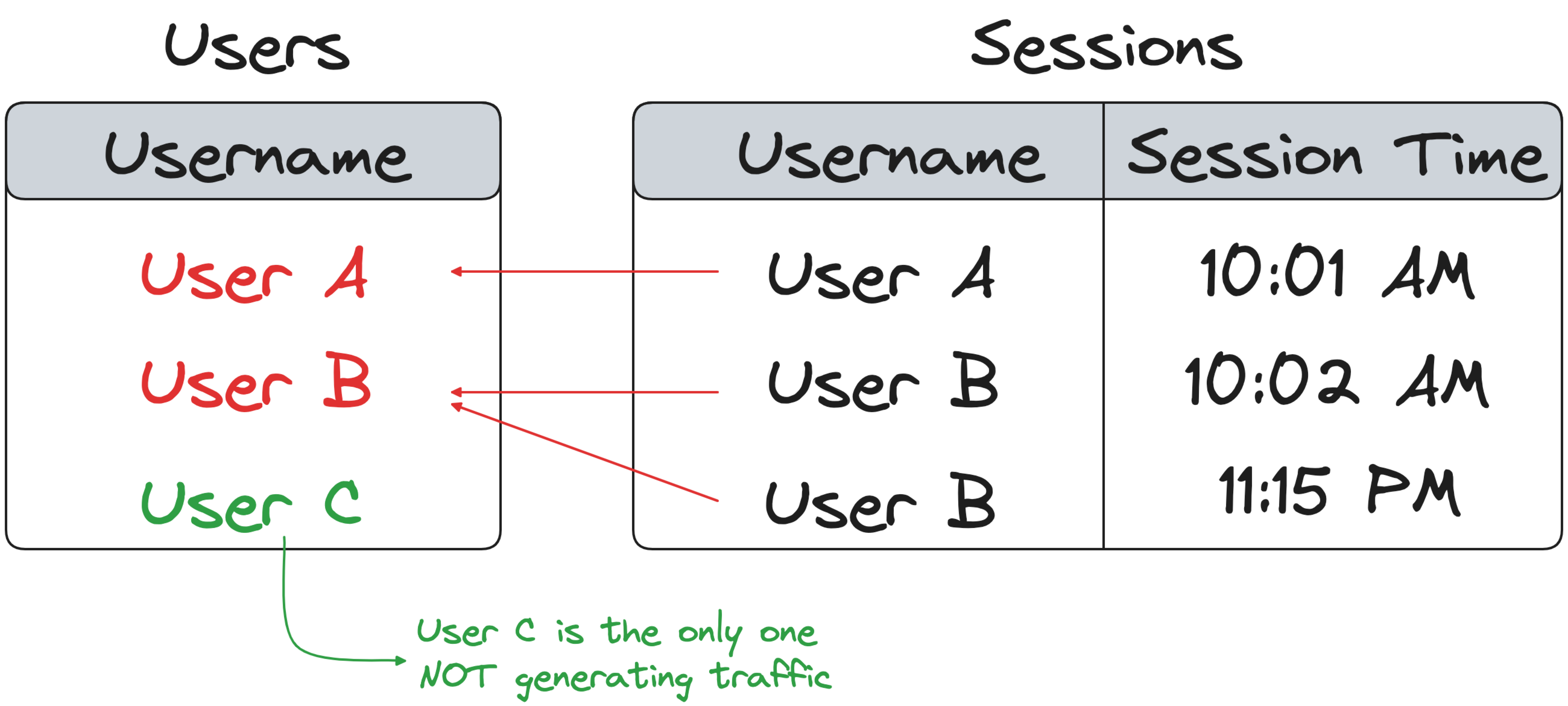
What does the NOT EXISTS operator return?
To fully evaluate the options available, we need to understand what the NOT EXISTS operator returns. The result of a NOT EXISTS operator is a boolean value, either TRUE or FALSE:
- If the subquery retrieves one or more records, the result of the
NOT EXISTSisFALSE - If the subquery retrieves no records, the result of the
NOT EXISTSisTRUE - If the subquery retrieves
NULL, the result of theNOT EXISTSisFALSE
It's very important to keep in mind the last example, specifically if we are checking the absence of fields that could be NULL.
Create a PostgreSQL database
Let’s start with the basics: a PostgreSQL® database! All the examples in this article work in any PostgreSQL; if you don’t have a PostgreSQL database handy you can rebuild the examples included in the article with an Aiven for PostgreSQL® database. You can create one for free in minutes by:
- Create an Aiven account
- Click on Create service
- Select PostgreSQL
- Define the cloud provider and region (the list of regions provided on the free plan is available in the dedicated documentation)
- Select the service plan: choose “free” (if unavailable, select a different cloud/region)
- Provide a service name, such as:
pg-non-exist
Once Aiven for PostgreSQL is up and running, you can find the Connection URI in the Overview tab. You can connect to the database by copying it and pasting in your terminal like:
psql [CONNECTION_URI]
Populate the PostgreSQL database
Next step is to populate the tables we’ll need for the example: a users table containing a list of hypothetical users, while sessions stores a list of user sessions that we are going to use to mimic the traffic. We can create the tables with:
CREATE TABLE USERS
(
id int PRIMARY KEY NOT NULL GENERATED ALWAYS AS IDENTITY,
user_name text
);
create table SESSIONS
(
id int PRIMARY KEY NOT NULL GENERATED ALWAYS AS IDENTITY,
user_name text,
dt timestamp
);
The above statements create a USERS and a SESSIONS table, each one having an ID automatically generated and a USER_NAME. The SESSIONS table also has a field called dt which records the session timestamp.
Initially we’ll focus on understanding the various options available in PostgreSQL, therefore we can populate the database with some demo data with:
INSERT INTO USERS (USER_NAME) VALUES
('Spiderman'),
('Wonder Woman'),
('Batman'),
('Sailor Moon');
INSERT INTO SESSIONS (USER_NAME, DT) VALUES
('Spiderman', CURRENT_TIMESTAMP),
('Wonder Woman', CURRENT_TIMESTAMP),
('Wonder Woman', CURRENT_TIMESTAMP);As per the last INSERT, only Spiderman and Wonder Woman users have recent activity, therefore a query looking for missing activity should provide the details of Batman and Sailor Moon.

In the following sections we’ll analyze the various options available in PostgreSQL to extract the above information. We’ll showcase the SQL, analyze the output of the EXPLAIN (telling us the predicted plan and performance) and then dig into the scenarios where a particular solution is optimal (and when is not).
Using EXISTS
The first option is to use PostgreSQL EXISTS subquery expression, adding the NOT in front to reverse the selection.
SELECT *
FROM USERS
WHERE NOT EXISTS
(
SELECT *
FROM SESSIONS
WHERE SESSIONS.USER_NAME = USERS.USER_NAME
);The above query for each of the users in the USERS table, performs a lookup into the SESSION tables to verify the presence of data for a specific user, and then provides only rows in the USERS table with no associated data. It’s important to notice that, as per documentation:
The subquery will generally only be executed long enough to determine whether at least one row is returned, not all the way to completion
Therefore, it’s an optimal solution in cases where retrieving the first row of the subquery’s resultset might be much faster than retrieving the total resultset, for example in a sessions table with millions of rows.
The EXPLAIN on the query is showing the usage of an Hash Anti Join, a dedicated PostgreSQL implementation of the Hash Join returning only rows that don’t find a match. The Anti Join is applied to a sequential scan on the USERS table, with a Hash join on the SESSIONS table
QUERY PLAN
---------------------------------------------------------------------
Hash Anti Join (cost=1.07..57.21 rows=2038 width=12)
Hash Cond: (users.user_name = sessions.user_name)
-> Seq Scan on users (cost=0.00..30.40 rows=2040 width=12)
-> Hash (cost=1.03..1.03 rows=3 width=12)
-> Seq Scan on sessions (cost=0.00..1.03 rows=3 width=12)
(5 rows)When EXISTS is slow
The query using EXISTS executes the subquery passing the condition for each USER to filter only the relevant rows. Therefore is not optimal for cases when the list of values to filter by is limited in size and common across the entire surrounding dataset.
In such cases, retrieving the entire filtering dataset once, and not per row, is more performant.
In our example, if we have only 100 sessions from 5 users, it is faster to just retrieve the list of usernames from the SESSIONS table and then apply it as a filter.
When EXISTS is fast
Since the query using EXISTS filters the subquery using fields of the surrounding dataset, it represents a better choice when there is a high cardinality in the table called by the subquery (SESSIONS in the example) that can be reduced with the filtering.
In our example, if we imagine a SESSIONS table containing 1000000 records from 10000 users, the query needs to evaluate on average only 100 rows (1000000/10000) for every USER.
Using NOT IN
An alternative option is to use the NOT IN subquery expression.
SELECT *
FROM USERS
WHERE USER_NAME NOT IN
(
SELECT USER_NAME
FROM SESSIONS
);The above query retrieves the list of distinct USER_NAMEs only once (see loops=1) from the SESSIONS table and then compares it with the data coming from the USERS table. For accurate results, the entire distinct list of USER_NAMEs needs to be retrieved from the subquery, making it slower in cases where the amount of sessions is huge and no dedicated index is present to speed up performance.
The query plan shows a sequential scan on the SESSIONS table and then the filter NOT applied to a sequential scan of USERS.
QUERY PLAN
---------------------------------------------------------------------------------------------------------------
Seq Scan on users (cost=29.63..63.88 rows=970 width=14) (actual time=0.044..0.045 rows=2 loops=1)
Filter: (NOT (hashed SubPlan 1))
Rows Removed by Filter: 2
SubPlan 1
-> Seq Scan on sessions (cost=0.00..25.70 rows=1570 width=12) (actual time=0.004..0.005 rows=3 loops=1)
Planning Time: 0.075 ms
Execution Time: 0.086 ms
(7 rows)
Note:
The NOT IN solution is equivalent to the EXISTS one only when where SESSIONS.USER_NAME is not null in the subquery is added or in cases when we are sure there are no NULLs (the column is declared not null) since NOT IN ( ..., null ) is never TRUE.
When NOT IN is slow
The query using NOT IN retrieves the entire filtering dataset from the subquery and then loops over the surrounding rows. With increasing cardinalities of the filtering dataset, the performance could suffer, since it needs to be retrieved all at once and kept in memory.
In our example, if we have 1000000 sessions from 10000 users, keeping in memory and iterating over the list of 1000000 usernames from the SESSIONS table will probably be time consuming compared to filtering the sessions per user.
When NOT IN is fast
When the cardinality of the filtering dataset is small, loading up in memory and iterating through it is the fastest option.
In our example, if we imagine a SESSIONS table containing 1000 records from 10 users, loading the entire 1000 usernames in memory and parsing them 10 times could be faster than re-querying the SESSIONS table multiple times.
Using <> ALL
A similar behavior can be achieved using the <> ALL subquery expression.
SELECT *
FROM USERS
WHERE USER_NAME <> ALL
(
SELECT USER_NAME
FROM SESSIONS
);
The behavior should be similar to the above query, however the query plan adds a Materialize step to store in a temporary table the result of the selection from the SESSIONS table.
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Seq Scan on users (cost=0.00..36385.00 rows=970 width=14) (actual time=0.021..0.030 rows=2 loops=1)
Filter: (SubPlan 1)
Rows Removed by Filter: 2
SubPlan 1
-> Materialize (cost=0.00..33.55 rows=1570 width=12) (actual time=0.002..0.002 rows=2 loops=4)
-> Seq Scan on sessions (cost=0.00..25.70 rows=1570 width=12) (actual time=0.003..0.004 rows=3 loops=1)
Planning Time: 0.067 ms
Execution Time: 0.067 ms
When <> ALL is slow
Compared to the NOT IN, the <> ALL solution adds a Materialize step. Therefore for small datasets that can easily fit in memory, materializing the result in a temporary table results in worse performances. For filtering datasets with high cardinality, likewise the NOT IN, iterating over the entire dataset for each of the surrounding queries could be time consuming if a more aggressive filtering can be used in the subquery.
When <> ALL is fast
Despite the <> ALL being similar to the NOT IN approach, the Materialize step makes it useful only in cases when the cardinality of results is not low enough to easily fit in memory. At the same time when the filtering dataset cardinality increases, a more aggressive filtering in the subquery with the EXISTS pattern could lead to better results.
Using LEFT JOIN
A different approach consists of using the LEFT JOIN statement, retrieving all the rows from the USERS table and joining them with the SESSIONS table. The resulting rows with NULL values for the SESSIONS related columns can be considered as not having activity.
SELECT *
FROM USERS LEFT JOIN SESSIONS
ON (SESSIONS.USER_NAME = USERS.USER_NAME)
WHERE SESSIONS.USER_NAME IS NULL;
Analyzing the plan created by the LEFT JOIN, we can see that two sequential scans are happening for both USERS and SESSIONS tables, with sorting based on USER_NAME and finally a Merge Anti Join applies.
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Merge Anti Join (cost=244.38..277.63 rows=893 width=38) (actual time=0.066..0.069 rows=2 loops=1)
Merge Cond: (users.user_name = sessions.user_name)
-> Sort (cost=135.34..140.19 rows=1940 width=14) (actual time=0.046..0.047 rows=4 loops=1)
Sort Key: users.user_name
Sort Method: quicksort Memory: 25kB
-> Seq Scan on users (cost=0.00..29.40 rows=1940 width=14) (actual time=0.007..0.008 rows=4 loops=1)
-> Sort (cost=109.04..112.96 rows=1570 width=24) (actual time=0.015..0.015 rows=2 loops=1)
Sort Key: sessions.user_name
Sort Method: quicksort Memory: 25kB
-> Seq Scan on sessions (cost=0.00..25.70 rows=1570 width=24) (actual time=0.004..0.004 rows=3 loops=1)
Planning Time: 0.375 ms
Execution Time: 0.107 ms
When LEFT JOIN is slow
The query using LEFT JOINS executes a Merge Anti Join over the after ordering the data coming from the two tables (surrounding and filtering). Therefore it is not optimal for cases when the list of values to filter by is limited in size. In such cases, retrieving the entire filtering dataset once, and iterating in the search for every line in the surrounding dataset, is more performant.
In our example, if we have only 100 sessions from 5 users, it is faster to just retrieve the list of usernames from the SESSIONS table and then apply it as a filter.
When LEFT JOIN is fast
By ordering the datasets based on the joining key, the query using LEFT JOIN optimizes the speed of comparison across them. Therefore it is worth using in cases of increased cardinality of the surrounding and filtering dataset. In such cases, the overhead of the ordering phase is absorbed by the optimized comparison phase.
In our example, if we imagine a SESSIONS table containing 1000000 records from 500000 users, the query will need to order the two datasets once, and then perform the filtering based on two ordered lists of USERNAMEs.
Using EXCEPT
The final option uses EXCEPT to remove from the list of users the ones found in SESSIONS. You can dig more into how to combine datasets in the dedicated documentation.
SELECT *
FROM USERS
WHERE USER_NAME IN (
SELECT USER_NAME FROM USERS
EXCEPT
SELECT USER_NAME FROM SESSIONS
);
The query plan for EXCEPT is a little bit more complicated, since the query:
- Starts with a sequential scan on
USERSandSESSIONS(the two subqueries) - Uses
HashSetOp Exceptto remove theUSER_NAMEs found inUSERSfrom the ones found inSESSIONS - Executes a sequential scan retrieving the data from
USERSwhich are in the list provided at the step before
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------
Hash Join (cost=160.18..194.68 rows=1940 width=14) (actual time=0.101..0.103 rows=2 loops=1)
Hash Cond: (users.user_name = "ANY_subquery".user_name)
-> Seq Scan on users (cost=0.00..29.40 rows=1940 width=14) (actual time=0.011..0.011 rows=4 loops=1)
-> Hash (cost=135.93..135.93 rows=1940 width=32) (actual time=0.070..0.071 rows=2 loops=1)
Buckets: 2048 Batches: 1 Memory Usage: 17kB
-> Subquery Scan on "ANY_subquery" (cost=0.00..135.93 rows=1940 width=32) (actual time=0.056..0.066 rows=2 loops=1)
-> HashSetOp Except (cost=0.00..116.53 rows=1940 width=36) (actual time=0.056..0.065 rows=2 loops=1)
-> Append (cost=0.00..107.75 rows=3510 width=36) (actual time=0.041..0.049 rows=7 loops=1)
-> Subquery Scan on "*SELECT* 1" (cost=0.00..48.80 rows=1940 width=14) (actual time=0.041..0.043 rows=4 loops=1)
-> Seq Scan on users users_1 (cost=0.00..29.40 rows=1940 width=10) (actual time=0.039..0.041 rows=4 loops=1)
-> Subquery Scan on "*SELECT* 2" (cost=0.00..41.40 rows=1570 width=16) (actual time=0.004..0.005 rows=3 loops=1)
-> Seq Scan on sessions (cost=0.00..25.70 rows=1570 width=12) (actual time=0.004..0.004 rows=3 loops=1)
When EXCEPT is slow
Using EXCEPT queries the USERS table twice. Therefore it can be an option for small datasets where other solutions like LEFT JOIN or EXISTS require a more iterative approach.
When EXCEPT is fast
The query using EXCEPT retrieves the list of surrounding and filtering datasets, excludes values with an HashSetOp operator, and then filters the data in the surrounding table with an Hash Join. The except query removes the need of negating the IN statement at the cost of parsing the surrounding table (USERS in our case) twice. Such a query can be useful when the cardinality of the surrounding table is limited (adding a small cost of parsing it two times), and when the cardinality of the IN list is way lower than the original cardinality of the NOT IN.
For example, if out of 100000 usernames, we filter out 999900 of them, using EXCEPT we are able to query the USERS table with an IN statement of 10 values.
PostgreSQL Performance at scale
As most developers know, validating solutions on a table containing a couple of rows is a recipe for disaster. However we can test the above solutions at scale by creating synthetic data in the USERS and SESSIONS tables. We can truncate (delete all records from) the tables and include data with the following script.
truncate table users;
truncate table sessions;
insert into users (user_name)
select 'USER' || generate_series
from (select generate_series(0,MAX_USERS)) data;
insert into sessions (user_name, dt)
select 'USER' || floor(random() * MAX_SESSIONS*0.8), CURRENT_TIMESTAMP
from (select generate_series(0,MAX_SESSIONS)) data;
Two parameters are available in the above script allowing us to test the solutions across a different set of scenarios:
MAX_USERSdefines the total number of usersMAX_SESSIONSdefines the total number of sessions
To evaluate the performance of the different options, we used the following scenarios:
| Example | MAX_USERS |
MAX_SESSIONS |
Small |
10000 | 10000 |
Increased Number of Clients |
1000000 | 10000 |
Increased Number of Sessions |
10000 | 1000000 |
Increased Clients and Sessions |
1000000 | 1000000 |
The Small scenario showcases 10000 users and session a limited amount of data. Then the Increased Number of Clients showcases a scenario where the number of “main iterations” on the CLIENTS table rises by 100x. The Increased Number of Sessions showcases the opposite, and a more realistic scenario, where the number of sessions is 100x the number of users. Finally the Increased Clients and Sessions showcases the results at high scales for both clients and sessions.
Set Timing
We can use psql and the timing command to obtain the execution time of the queries. To enable timing we can just type:
\timing on
From now on every command we are going to execute will provide details about the execution time
PG performance results
The following are the performance results in milliseconds of various configurations, with the top axes showing the number of users and sessions (e.g. 10000u/10000s is with 10000 users and 10000 sessions).
| Syntax | 10000u/10000s | 1000000u/10000s | 10000u/1000000s | 1000000u/1000000s |
NOT EXISTS |
⚠️124 | ✅2523 | ✅555 | ✅1656 |
NOT IN |
✅85 | ✅1891 | 🔴Stopped after 2 minutes | 🔴Stopped after 2 minutes |
<> ALL |
🔴4724 | 🔴Stopped after 2 minutes | 🔴Stopped after 2 minutes | 🔴Stopped after 2 minutes |
LEFT JOIN |
⚠️200 | ✅2914 | ✅559 | ✅1891 |
EXCEPT |
✅74 | ⚠️4171 | ✅198 | ⚠️8749 |
We can immediately understand that while NOT EXISTS and LEFT JOIN are slower on low cardinalities, due to the respective overhead of subselection and result ordering, they manage to scale almost linearly with the number of users. On the other side, the NOT IN is among the fastest when the amount of data is small and when the number of clients rises, but, as soon as the number of sessions (driving the list of usernames to exclude) increases, the performance starts degrading.
The <> ALL example showcases how the materialization slows down the performance on small datasets, and how the query pattern (similar to the NOT IN) can’t handle the big load volume. Finally the EXCEPT is a tradeoff, working well on small datasets but not scaling as well as the NOT EXISTS and LEFT JOIN on huge volumes.
Conclusion - What to choose?
PostgreSQL's flexibility and rich language provides several methods to implement the NOT EXISTS clause, finding the correct implementation for your cardinality can provide a performance boost on your queries allowing you to optimize your resource usage! You can even use automatic query optimization tools that will help you optimize PostgreSQL's slowest queries.
For smaller datasets the NOT IN solution provides the best performance, retrieving the list of excluded elements once and iterating over the surrounding datasets. However, for increased cardinalities, iterating over an unsorted list of values quickly becomes a bottleneck. When data volumes rise, using the NOT EXISTS or LEFT JOIN and having the benefit of an aggressive filtering query or sorted comparison will produce the fastest results.



One thought on “5 Ways to implement NOT EXISTS in PostgreSQL”
Comments are closed.