This post's content
In modern application development, we often abstract direct access to the database layer from the application layer using an ORM. This allows us to worry less about exactly how the data is retrieved using SQL, and more about writing our application. That said: there are scenarios where it’s useful to examine and optimize the underlying SQL. In this blog, we’ll use Prisma, a Javascript ORM, and we’ll optimize the Prisma raw queries SQL generated using EverSQL.
Why should we care about the raw SQL Prisma produces? Most of the time, Prisma does a good job at generating the SQL necessary to talk to the database, but sometimes it leaves something to be desired in terms of optimizing our database calls. EverSQL can help you streamline this process, which is especially useful if you don’t have a database administrator on staff!
Prisma's Developer Advocate Alex Ruheni wrote an excellent blog post on how to improve Prisma query performance with indexes, however, finding the right index to create still relies on a human to detect and implement. With EverSQL you can get index suggestions at your fingertips.

The starting point - a Prisma app
If you’re working with Prisma, you’ll have your application models defined in a schema.prisma file, containing the client, the provider and the object definitions like the following.
generator client {
provider = "prisma-client-js"
}
datasource db {
provider = "postgresql"
url = env("DATABASE_URL")
}
model User {
id Int @id @default(autoincrement())
email String @unique
name String?
posts Post[]
}
model Post {
id Int @id @default(autoincrement())
title String
content String?
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
}
The above defines the datasource db as a PostgreSQL database with the connection URL stored in the DATABASE_URL variable. It also declares User and Post models that are used to store the app information. Our app stores hence these two tables .
The Prisma function definition
The above file defines the basics of our application backend storage. However, if, for example, we want a method to retrieve all the Users with less than 3 published posts, we could write the following function defined in a file called query.ts.
async function main() {
const usersWithPosts = await prisma.user.findMany({
include: {
posts: {
where: {
AND: [
{published: true},
{id: {lt:3}}
]}
}
},
})
When invoking the file with:
npx ts-node query.ts
We get the list of users
[
{
id: 1,
email: '[email protected]',
name: 'Steve',
posts: [
{
id: 1,
title: 'title0',
content: 'content0',
published: true,
authorId: 1
},
{
id: 2,
title: 'title1',
content: 'content1',
published: true,
authorId: 1
}
]
}
]
Set Prisma client SQL query logging
The above works, so what’s the problem? The problem arises if we want to understand and optimize the queries that we run against the database. To do so, we first need to understand which SQL Prisma is generating. By adding the log custom parameters to the PrismaClient definition we can print all the queries that are executed against the database.
const prisma = new PrismaClient({
log: [
{
emit: "event",
level: "query",
},
],
});
prisma.$on("query", async (e) => {
console.log(`${e.query} ${e.params}`)
});
The prisma.$on function logs the query (${e.query}) and its parameters (${e.params}).
Therefore, the next time we execute the function, the output showcases the SQL query alongside the results.
SELECT "public"."User"."id", "public"."User"."email", "public"."User"."name" FROM "public"."User" WHERE 1=1 OFFSET $1 [0]
SELECT "public"."Post"."id", "public"."Post"."title", "public"."Post"."content", "public"."Post"."published", "public"."Post"."authorId" FROM "public"."Post" WHERE (("public"."Post"."published" = $1 AND "public"."Post"."id" < $2) AND "public"."Post"."authorId" IN ($3)) OFFSET $4 [true,3,1,0]
[
{
id: 1,
email: '[email protected]',
name: 'Steve',
posts: [
{
id: 1,
title: 'title0',
content: 'content0',
published: true,
authorId: 1
},
{
id: 2,
title: 'title1',
content: 'content1',
published: true,
authorId: 1
}
]
}
]
The following are two SQL statements:
- Retrieving the list of users with
SELECT "public"."User"."id", "public"."User"."email", "public"."User"."name" FROM "public"."User" WHERE 1=1 OFFSET $1
- Retrieving the list of posts for a specific user with:
SELECT "public"."Post"."id", "public"."Post"."title", "public"."Post"."content", "public"."Post"."published", "public"."Post"."authorId" FROM "public"."Post" WHERE (("public"."Post"."published" = $1 AND "public"."Post"."id" < $2))
The above SQL statements are parametrized, therefore we see the SQL statements with placeholders ($1, $2 … ) for the filter values. In addition, alongside the statement, we print the values for the various parameters:
[0]retrieves data in the first query fromOFFSET 0(starting reading from the first page)[true, 3,1,0]applies:- A filter on
"public"."Post"."published" = true - A filter on
"public"."Post"."id" < 3 - A filter on
"public"."Post"."authorId" IN (1) - Retrieves data in the first query from
OFFSET 0
- A filter on
We have pretty much all the information needed to start digging into database optimization!
Optimize the Prisma raw query
The next question, now that we have the SQL statements, is how to optimize these queries. We could spend time on research or just head to EverSQL query optimiser and have the reply in a minute.
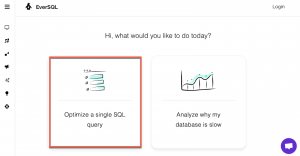
To do this in EverSQL, select:
- Optimize single query
- The backend database of choice (PostgreSQL in the example)
- The hosting provider
- The framework (Prisma (node.js) in the example)
We then copy the Prisma raw SQL, optionally pasting also the database schema, and then click All done, optimize the query.
Note: you can retrieve the database schema by connecting to the database and executing the query that you can copy/paste from the EverSQL UI
Since we are using Prisma, we’ll not be able to change the SQL generated, therefore EverSQL will only suggest improvements to apply to the database to make it more performant, like a database index in this case. There’s always the following option to tick or untick in cases we are able to change the underline SQL.
![]()
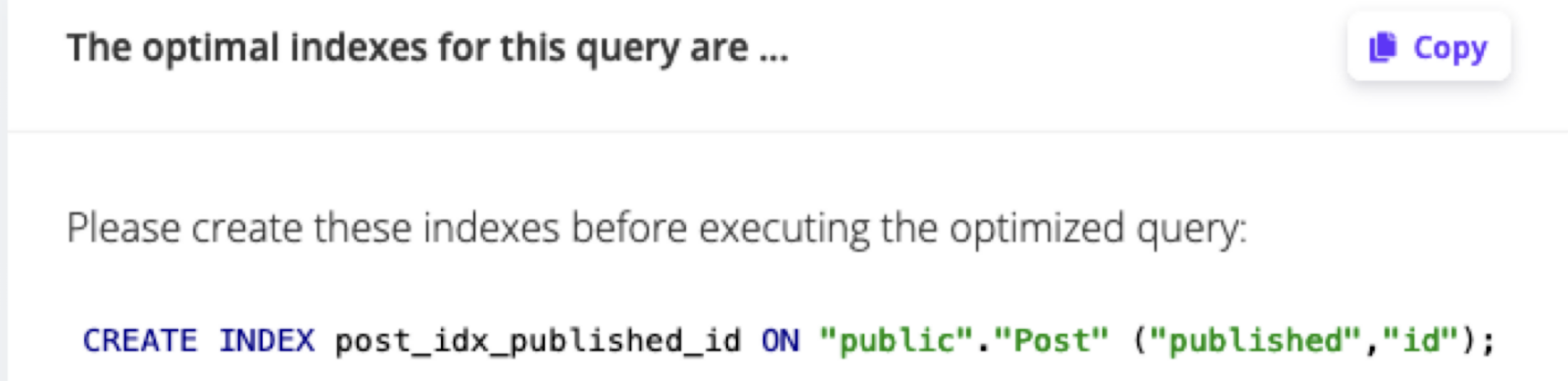
EverSQL optimisation engine suggested to create an index called post_idx_published_id
Translate a SQL index suggestion to Prisma
The above suggestion is in pure PostgreSQL SQL, How do we translate it to Prisma? Let’s review the index optimisation suggestion:
CREATE INDEX post_idx_published_id ON "public"."Post" ("published","id");
The above index:
- Is created on top of the
"public"."Post"table - Is defined on top of the
publishedandidcolumns
Therefore, we can head to the schema.prisma file where our data structure is defined, and, extend the Post model with the @@Index definition
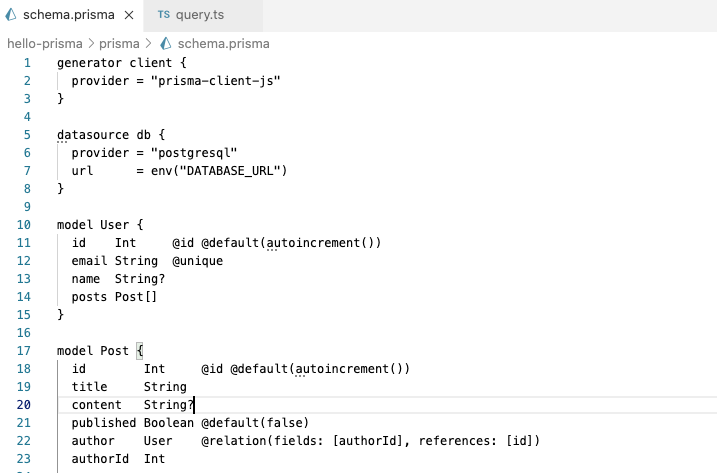
model Post {
id Int @id @default(autoincrement())
title String
content String?
published Boolean @default(false)
author User @relation(fields: [authorId], references: [id])
authorId Int
@@index([published, id])
}
Compared to the previously defined Post model, we added the line @@index([published,id]) which adds the index using the published and id columns. To implement the new index in the database via Prisma we need to create a migration file with:
npx prisma migrate dev --create-only
And provide a name to the migration like add_index. Once done, Prisma creates a subfolder under migrations containing a migration.sql file that contains the SQL that will be applied to PostgreSQL:
-- CreateIndex
CREATE INDEX "Post_published_id_idx" ON "Post"("published", "id");
We can apply the migration with:
npx prisma migrate dev
If we now check in the database, we should see the index created and our query performance optimized!
Additional ways to optimize your Prisma raw queries
The above process only touched the tip of EverSQL functionalities. By uploading your database metadata during the SQL analysis phase, EverSQL is able to better understand your database structure and, along with the query information, optimize it for your workload.
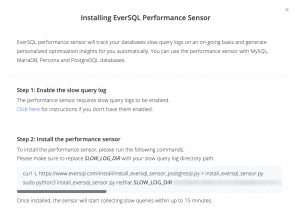
Even more, if your application hits your with multiple different queries, uploading your slow query log or installing a sensor and connecting your database to EverSQL, provides you the ability to continuously monitor the workload and receive optimization suggestions enhancing the system as a whole.
Make Prisma queries faster
Tools like Prisma are great for abstracting the application from the underlying technology. That said, from time to time we still need to understand and optimize the database structures and SQL statements to improve application performance.
A trial and error process of optimizing our database calls is dangerous, as this can decrease performance if done incorrectly, or even cause application failures. We can use Prisma raw query SQL’s printing option and AI-driven tooling like EverSQL to improve performance in a programmatic, repeatable fashion, based on your query patterns.



