This post's content
PostgreSQL offers several ranking functions out of the box. Let's look into the differences and similarities between three of them: RANK(), DENSE_RANK() and ROW_NUMBER().
For the sake of comparison, we'll work with the following demo table and values:
CREATE TABLE fruits AS
SELECT * FROM (
VALUES('apple'),('apple'),('orange'),
('grapes'),('grapes'),('watermelon')) fruits;
ROW_NUMBER Function
This is the simplest of all to understand. This function will just rank all selected rows in an ascending order, regardless of the values that were selected.
Example:
select name, ROW_NUMBER() OVER(ORDER BY name) from fruits;
The results:
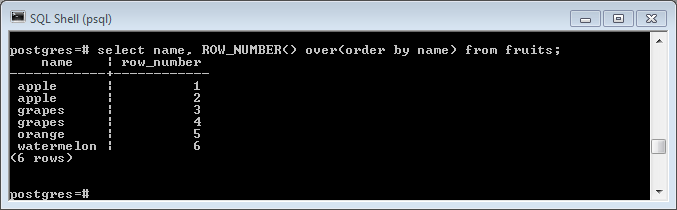
You can see above that the results are ordered by the column we declared in the ORDER BY clause, and ranked accordingly.
RANK Function
This function is very similar to the ROW_NUMBER() function. The only difference is that identical rows are marked with the same rank. Also, please note that if the function skipped a number while ranking (because of row similarity), that rank will be skipped.
Example:
select name, RANK() OVER(ORDER BY name) from fruits;
The results:
![]()
You can see above that identical rows (such as 'apple') were ranked with the same number. Also, once 'apple' was ranked with the number '1', the number '2' was skipped because the second row is identical. Therefore, the next row ('grapes') received the rank '3'.
DENSE_RANK Function
When using DENSE_RANK, the same rules apply as we described for RANK(), with one difference - when similar rows are detected, the next rank in line isn't skipped.
Example:
select name, DENSE_RANK() OVER(ORDER BY name) from fruits;
The results:
![]()
As you can see above, no ranks were skipped, all 1 to 4 are there. When identical rows were found ('apple'), they were given the rank '1', but the rank '2' wasn't skipped and was given to the next non-identical row in line ('grapes').
Summary
As you can see, different ranking functions have different goals. Now you're left with deciding which one is the best fit for your needs.



