This post's content
Right-sizing database instances is the process of adjusting your database instances’ size to match the workload generated by the application. In most cases, the incentive to right-size your database instances will be to lower the cloud infrastructure’s costs, ideally without compromising on performance.
In this post we’ll guide you through how to analyze the instance’s used resources, in an effort to identify opportunities to save on your RDS costs.
MySQL has a lot of “moving parts” which may contribute to the amount of memory it needs to operate efficiently. Just to list a few of the most impactful factors: fixed-size buffers (query cache, innodb buffer pool size), the database’s workload (query connections, query buffers), replication internals (replication connections, binary log caches) and more.
When looking for down-sizing opportunities, we’re searching for instances with too much memory, which isn’t really used by the database for the current workload. So how can we tell whether the database really needs the amount of memory that was allocated to it?
Looking at the memory usage of MySQL’s process at the OS level isn’t a good indicator, as large portions of the memory (such as the innodb buffer pool) are pre-allocated by the process, but not necessarily used. A better indicator can be found by analyzing the usage patterns of what is usually the largest memory consumer - the innodb buffer pool.
The innodb buffer pool is a fixed-size memory area where the database’s engine caches the table’s data and the indexes data. Ideally, the innodb buffer pool should have enough space to hold the data and indexes which are commonly accessed by the database, so that all queries will be served using the memory, with limited amount of disk access required. So if your database needs to access 5GB of data and indexes on a regular basis, it doesn’t make a lot of sense to preallocate 100GB to the innodb buffer pool.
To analyze the usage patterns of the innodb buffer pool, you can use MySQL’s built in command `show engine innodb status`. In the command’s output, you should look at:
- Free buffers - The total size (in pages) of the buffer pool free list. What this actually means is that if your system is fully warmed up and this number is rather high, it probably means you’re allocating too much memory for your innodb buffer pool, as some of it isn’t really utilized. Tracking this indicator over time, in both regular hours and during workload peaks will show you the full picture. High value of free buffers over time may be an indicator for a memory down-sizing opportunity.
- Pages evicted without access - The per second average of the pages evicted without being accessed from the buffer pool. If this number is larger than 0, it means that there are times where data is loaded to the buffer pool and pulled out from it without it even being actually used. Having a number larger than zero for this indicator over time may mean that you didn’t allocate enough memory to the innodb buffer pool, which may in turn indicate that you shouldn’t down-size this instance, as it may even need more memory to perform optimally.
This is an example of the output shown by the innodb status command:
BUFFER POOL AND MEMORY
----------------------
Total large memory allocated 6596591616
Dictionary memory allocated 415137
Buffer pool size 393216
Free buffers 378927
Database pages 14285
Old database pages 5428
….
0.00 reads/s, 0.00 creates/s, 0.00 writes/s
No buffer pool page gets since the last printout
Pages read ahead 0.00/s, evicted without access 0.00/s, Random read ahead 0.00/s
….
This sample demonstrates an output that may indicate that the database has too much memory allocated to it.
Matching the right amount of vCPUs to efficiently serve your applications workload can be a difficult task. To locate opportunities for instance down-sizing, we should look at the CPU usage over time, to see whether the amount of vCPUs matches the actual requirements from our workload.
Amazon RDS Performance Insights allows you to quickly assess the existing load on your database. By looking at the CPU usage over time, you can identify which instances are not actually using their allocated resources and can be considered for down-sizing.
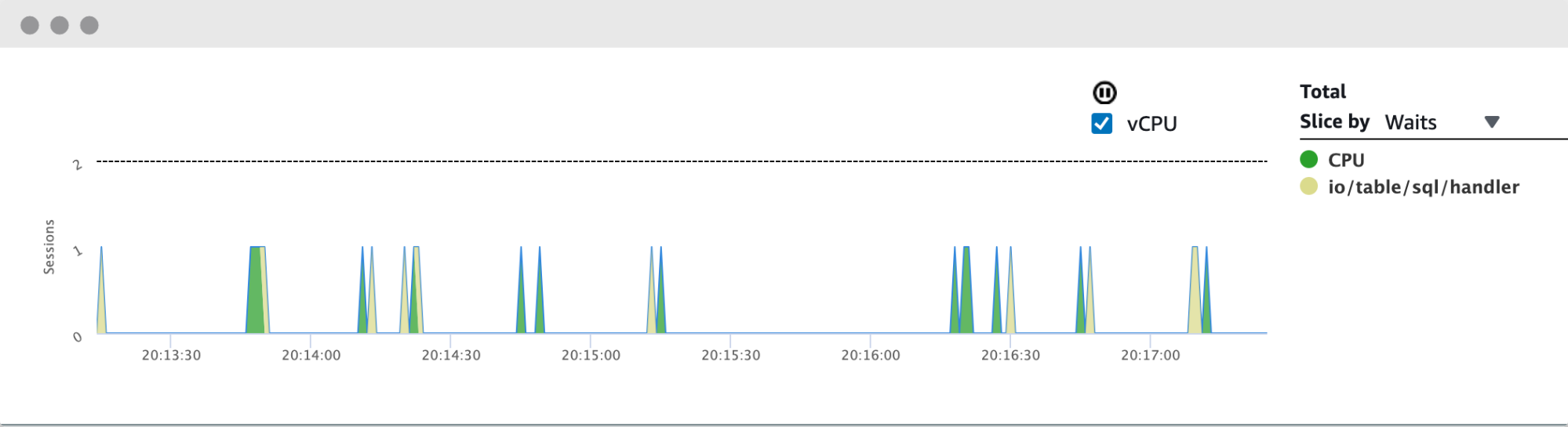
For example, looking at the database load chart for this instance, we can see that there is no more than one vCPU used simultaneously at any given time, while the instance has 2 vCPUs allocated to it (as indicated by the dotted flat line at the top of the chart). If you’re seeing a similar pattern for your instances over time (in both regular hours and workload peaks), that’s a strong indication that you may consider down-sizing the instance by reducing the amount of vCPUs.
Resizing instances based on users behavior patterns
By analyzing your workload, you can identify opportunities for down-sizing instances based on your user behavior patterns. For example, if your users are all from a specific time zone, maybe you can consider down-sizing the instance after a certain hour, when the workload reduces significantly.
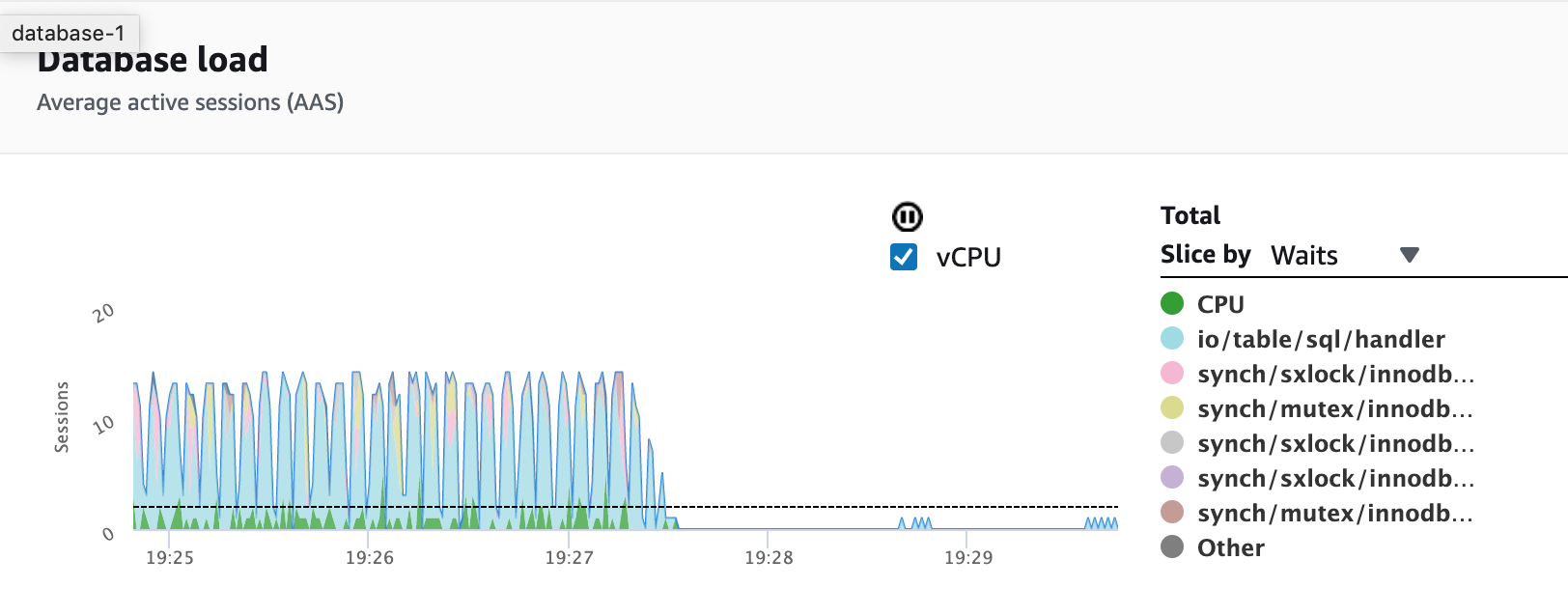
In the load charts above, Performance Insights can show us that around 19:30, the workload on the instance reduces significantly. Tracking this behavior over time can help us understand our users behavior patterns and apply automatic resizing actions.
Please keep in mind that re-sizing the instance may require downtime when working with a single instance for each database. To avoid any downtime, you can consider working with a multi-AZ RDS environment, which will allow you to apply the changes to a reader instance before actually switching it (failover) to act as your production writer instance.
Actively driving CPU and memory usage down
In some cases, after analyzing the CPU and memory usage on your instances, you may find that you can’t down-size the instance without actually reducing the workload on that instance.
Poorly optimized SQL queries tend to require a significant amount of resources, which in turn forces you to choose a ‘larger’ instance type than you would need if those queries were tuned for optimal performance.
AWS RDS Performance Insights can help you identify which SQL queries take up most of your resources, so you could focus on optimizing those queries.
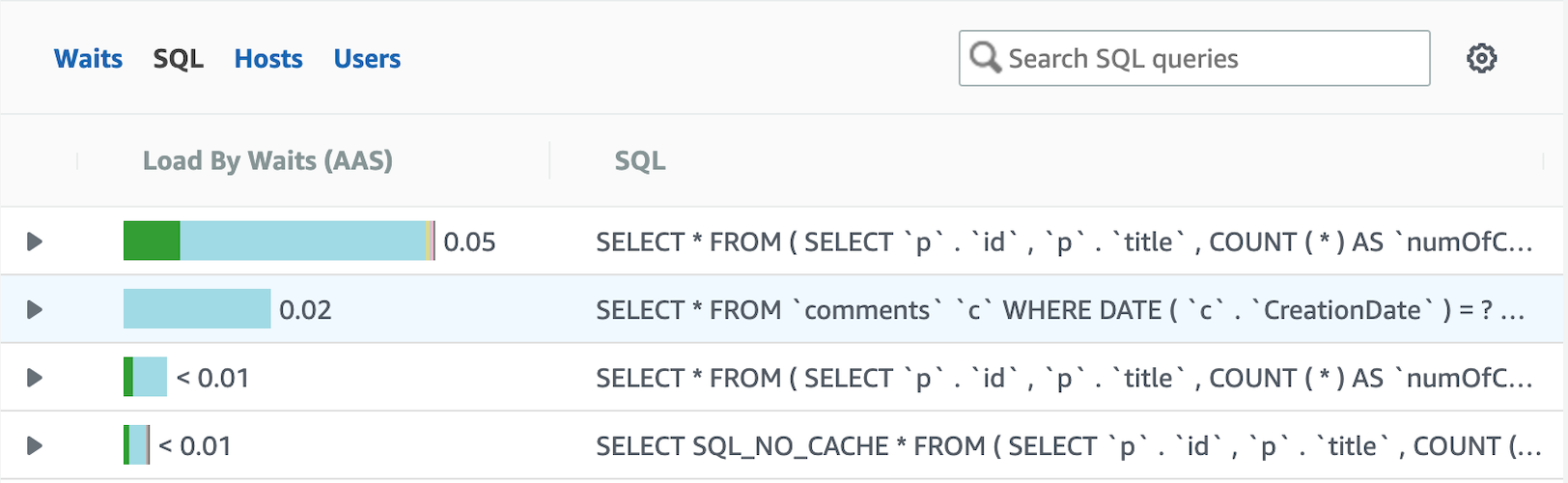
As the query optimization process can be complex and time consuming, you can integrate Performance Insights with EverSQL’s sql query optimization product, which will allow you to optimize slow queries automatically, directly from the Performance Insights interface.
Wrapping up
Right-sizing RDS instances is a great way to drive RDS costs down. It can be done by analyzing the actual resource usage on your instances to identify down-sizing opportunities which do not require compromising on performance or availability. Also, you can take actions to actively optimize your SQL queries and your database workload and drive the CPU and memory usage down, which in turn can allow you to safely down-size your RDS instances while keeping the same service level.



