

















EverSQL is the fastest way to optimize your PostgreSQL & MySQL databases automatically.
It's used by over 100,000 engineers as a PostgreSQL & MySQL optimizer, to optimize SQL queries.
Our customers report their queries are 25X faster on average, just minutes after getting started.
Save your team 140 weekly hours on average by optimizing your SQL queries online for free.
EverSQL is 100% non-intrusive, and doesn't access any of your databases' sensitive data.
Choose your database type, the platform, and submit a query for optimization. Then, install the performance sensor for ongoing performance insights.

Smart AI-based algorithms will optimize your PostgreSQL and MySQL queries by automatically re-writing and indexing them. EverSQL will tell you exactly what changed and how the magic works.
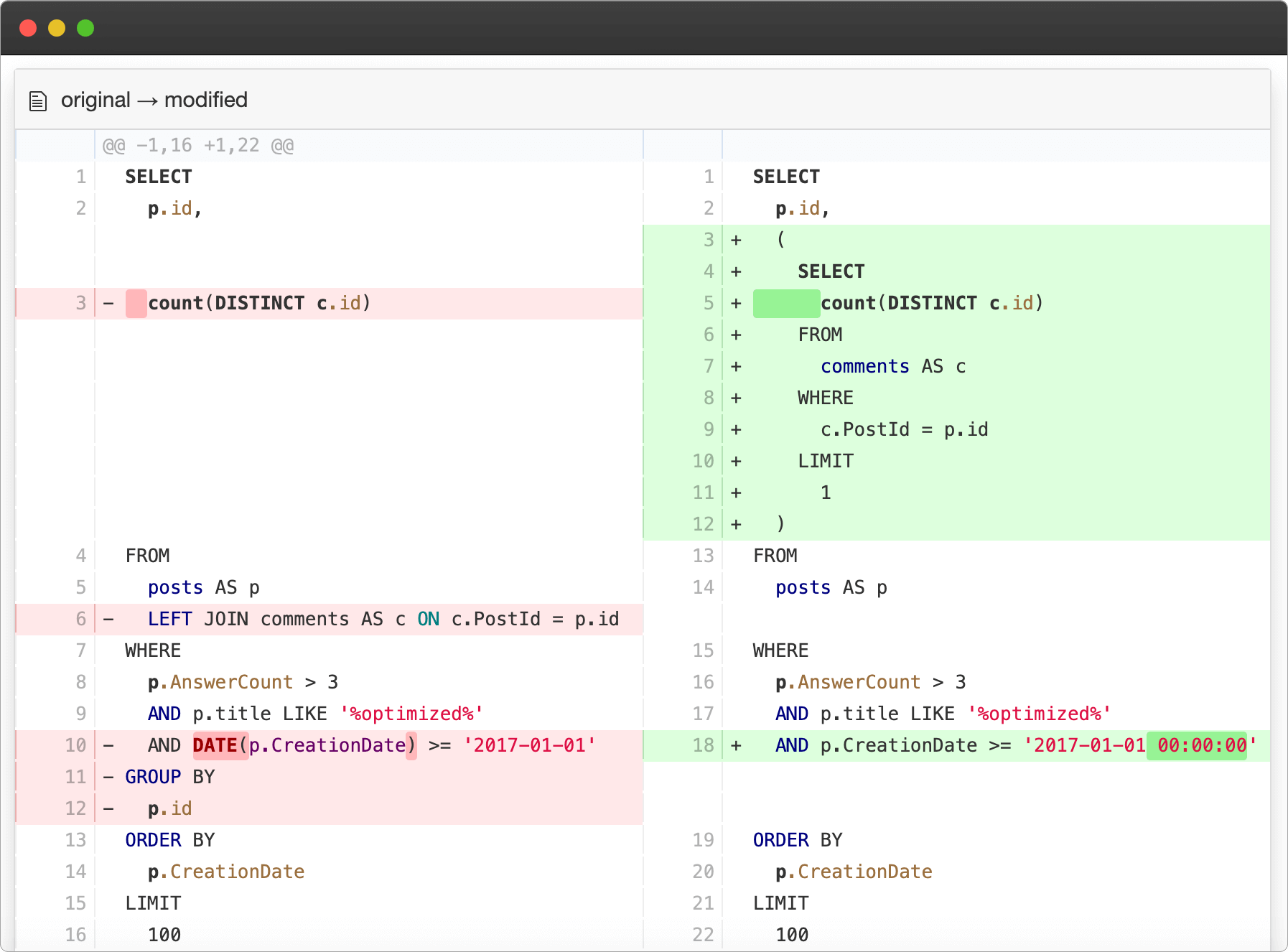
EverSQL's non-intrusive sensor will monitor your PostgreSQL and MySQL databases performance on an ongoing basis, generate optimization insights that are quick and easy to understand and implement.
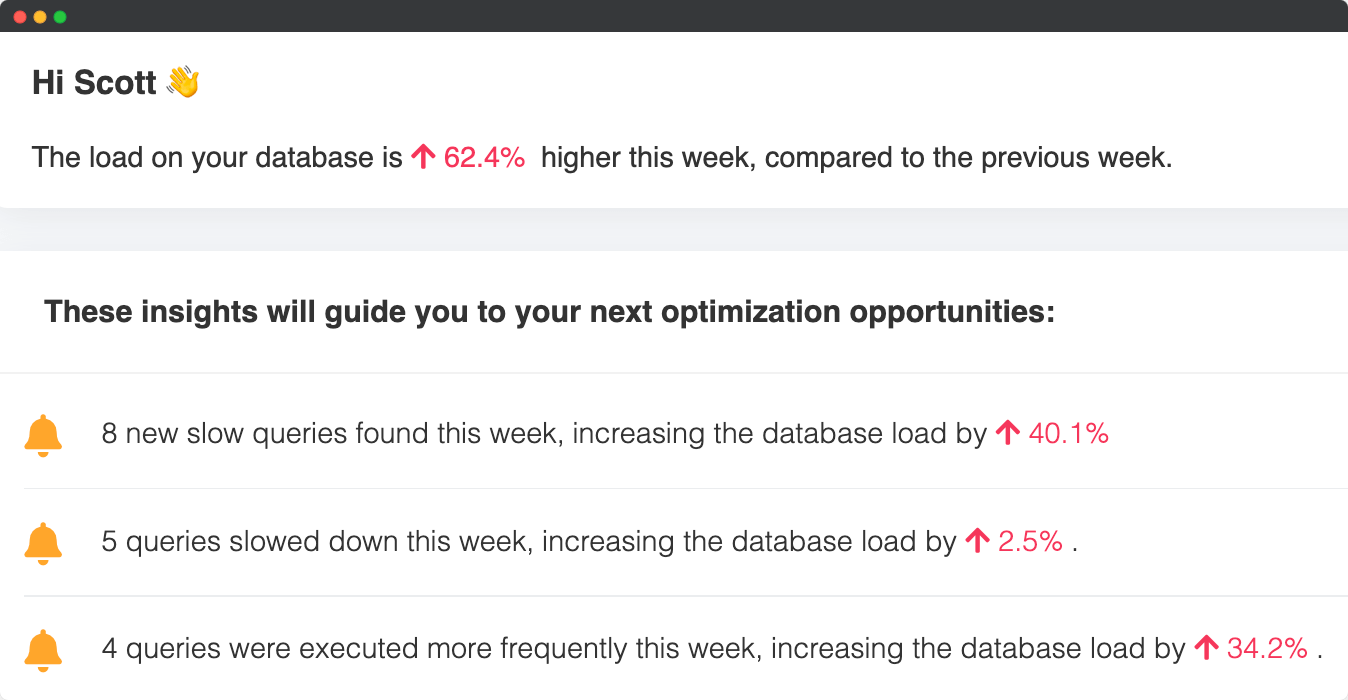
EverSQL helps reduce your PostgreSQL and MySQL database monthly cost by providing ongoing recommendations such as deletion of redundant indexes and schema optimizations. Applying these recommendations will optimize your database performance, reduce CPU usage, memory usage, and storage costs.
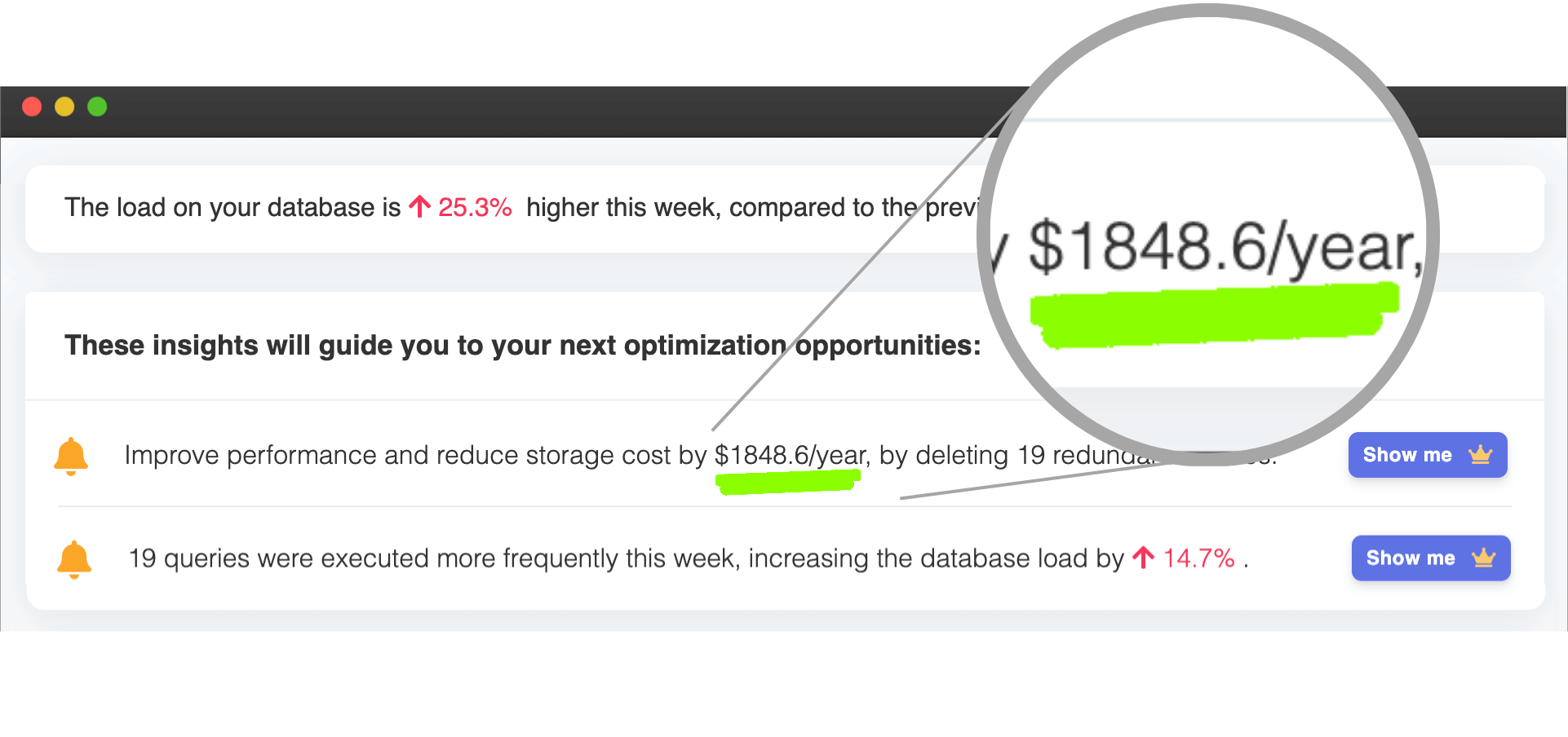

Start optimizing SQL queries automatically with EverSQL and experience the magic.
Start Optimizing for Free